By Al Sutton
A model of the problem
|
8 |
16 |
15 |
17 |
3 |
6 |
4 |
7 |
15 |
3 |
13 |
2 |
15 |
1 |
|
21 |
12 |
6 |
8 |
7 |
11 |
2 |
9 |
8 |
5 |
3 |
19 |
14 |
16 |
|
22 |
1 |
16 |
18 |
6 |
19 |
11 |
5 |
13 |
17 |
12 |
20 |
22 |
10 |
|
21 |
16 |
14 |
2 |
6 |
13 |
10 |
7 |
22 |
9 |
9 |
1 |
21 |
10 |
|
13 |
13 |
5 |
19 |
5 |
21 |
4 |
2 |
20 |
2 |
3 |
8 |
16 |
16 |
|
20 |
7 |
6 |
7 |
2 |
19 |
18 |
12 |
21 |
8 |
9 |
21 |
3 |
2 |
|
4 |
16 |
13 |
2 |
21 |
8 |
3 |
12 |
15 |
14 |
19 |
16 |
18 |
16 |
|
17 |
6 |
14 |
17 |
16 |
6 |
19 |
20 |
18 |
17 |
8 |
8 |
10 |
7 |
|
19 |
18 |
5 |
14 |
21 |
9 |
12 |
3 |
18 |
2 |
17 |
9 |
5 |
13 |
|
15 |
9 |
9 |
20 |
10 |
11 |
2 |
15 |
18 |
14 |
6 |
14 |
8 |
17 |
|
20 |
21 |
2 |
3 |
20 |
9 |
22 |
2 |
21 |
20 |
15 |
3 |
10 |
3 |
|
4 |
20 |
15 |
8 |
14 |
4 |
15 |
14 |
18 |
3 |
11 |
8 |
5 |
16 |
|
6 |
5 |
1 |
10 |
12 |
12 |
18 |
14 |
6 |
16 |
4 |
5 |
17 |
16 |
|
7 |
10 |
7 |
5 |
18 |
21 |
3 |
15 |
6 |
2 |
8 |
2 |
20 |
5 |
|
15 |
19 |
7 |
3 |
20 |
11 |
6 |
11 |
6 |
16 |
5 |
5 |
4 |
10 |
|
14 |
11 |
9 |
7 |
3 |
21 |
8 |
10 |
19 |
4 |
9 |
21 |
16 |
10 |
What is the probability of finding the “word” 123 in the sample matrix above at any ELS between ELS=1 and the maximum ELS for the 224 cell matrix shown? That’s how the question is usually conceived. However, we’re really interested in the probability of seeing the sought after word in the matrix in some reasonable alignment with the central search phrase. The “discovery” of a word that fits, but isn’t readable isn’t really acceptable. An acceptably oriented find is intuitively much less probable than a randomly oriented find, and this is where many critics go wrong. The problem really has to be broken down and solved piecewise for each column, each row, and each diagonal that you might accept as meaningful. Here comes the human decision process again. Don’t forget the card players dictum that one peek is worth a thousand finesses. Once you’ve seen what is there, overly limiting the calculation to what you see is “peeking” then cheating. For the sake of simplicity (and conservation of time), I’ll limit the solution to all skips from one-to-five without diagonal offsets. That’s how I always start my searches anyway. I’ll compare that with the usual, more conservative approach.
The Solution for 5766
1. We have a central search term identified, and the software has presented us with a well aligned matrix of 69 columns and 24 rows or 1656 characters.
2. I will use the letter distribution for the Torah as the basis for doing the search on the letters for HC 5766 (AD 2006). I don’t want to skew the result by developing a matrix specific distribution. I’m basically lazy. I don’t want to have to redo this solution for every matrix.
3. The probability of finding the characters for 5766 in single sample is approximately
0.0920 x 0.0589 x 0.0512 x 0.0060 x 0.1001 = 1.67 x 10-7.
4. Letter order is important. The probability estimate based on the letter distribution has to be multiplied by (1/5!=1/120) to give the probability for actually finding the word in the right letter order or: 1.67 x 10-7 x 0.00833 = 1.39 x 10-9 for a single unidirectional sample.
5. The total number of samples, the expected number of finds, and the estimated probability for the traditional solution is now determined as:
5.1 Maximum skip is given by: 1656 / (5-1) = 414
5.2 Number of bidirectional samples between skip = 1 and 414 is: 1,364,552
5.3 The expected number of 5766’s in the frame: 1,364,552 x 1.39 x 10-9 = 1.90 x 10-3
5.4 In other words, the random expectation appears to be about 2 finds in 1,000 matrices.
6. The more difficult solution is the piecewise fit that includes the readability criterion:
6.1 The maximum skip in a column is 6, and there are 69 of them.
6.2 The maximum skip in a row is 17, and there are 24 of them
6.3 The maximum skip in a full diagonal is 6, and there are 45 of them
6.4 Then there are the diagonals in the corners that range in length from 23 to 1, but only the diagonals from 23 to 5 can give readable results, so there are 36 of them.
6.5 The total number of samples is 71,048 across the 4 categories of readable words
6.5 The expectation of finding a readable 5766 is estimated at 71,048 x 1.39 x 10-9 =
9.89x 10-5, or only about 1 in every 10,000 frames.
6.6 Using diagonal offsets will increase the expectation of finding a readable date, but not by very much.
Conclusion: If you see a readable 5766 (AD 2006) in the same frame as your search term, it’s likely significant in a statistical sense. If you see multiples of the same year, the odds jump to better than one in a million very quickly. A similar calculation for 5770 (AD 2010) yields an estimate of about 4 readable years per 100 frames.
An experiment:
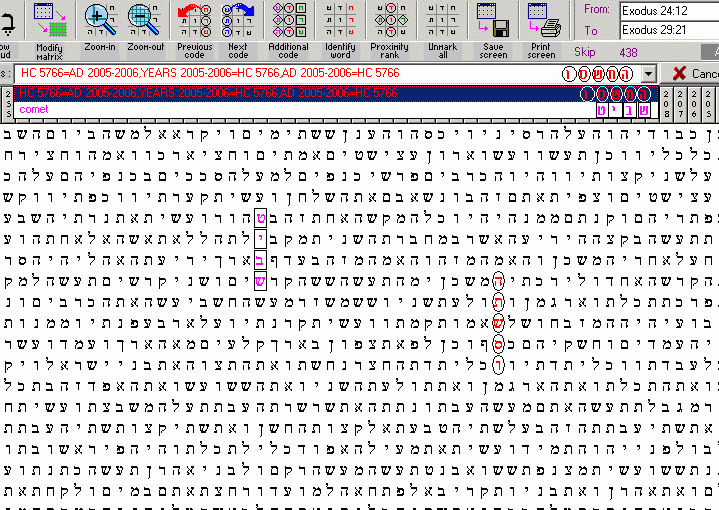
We’ve seen a lot written about the potential for comet and asteroid impacts causing terrible grief (see any of the papers by Duncan Steele, the Australian astronomer or several of the Bible Codes on the Exodus 2006 website). A year date of 5776 was hypothesized as long ago as the first Bible Code book by Michael Drosnin. How hard would it be to find some basic evidence? My Bible Codes 2001 software predicts approximately 10,000 instances of “comet” between ELS skips 1 and 10,000. Based on the above argument, we should expect to find about 1 matrix with the 5776 date correlated to “comet” (Tet, Yod, Bet, Shin). The software declares in finds 48.
We’ve all experienced the disappointment of finding fewer hits than the software declared. Sometimes that fewer is zero. So I started a manual search, expecting that it might take more work than I wanted, yet as soon as ELS 438, Exodus 25:36-26:22, I found a visually compelling match with comet and “5766” at the same skip only a few columns apart. A quick inspection of the words around it yielded many of the end-time words and phrases we’ve come to expect, many interlocking with either “comet” or “5766”. Comet correlates to 5766 beyond reasonable expectation for a random correlation.